一次awk疑惑分析
今天在做数据分析的时候,需要对原始文件做排重处理,网上看到一个方式如下所示
1 | root@localhost cc]# cat 2.txt |
但是按照awk模式理解,上面的语法是没有用到BEGIN 和 END, 那就是主体block, 但是主体block 的语法为 /pattern/ {command} ,有感觉不符合
分析
1、上面语句中的{print} 默认是打印所有符合条件的列, 是 print $0 的简写,
2、a[$1]++ 拆分开来看,a[$1] 是把第一列作为数组下标,也就是 a[$1] 的结果是个数字 这样才能执行后面的++ 操作
3、既然如此,那就改造语句执行如下
1 | root@pts/0 $ cat repeat.txt |awk '{print a[$1]++, $0}' |
4、从上面的对比结果发现,非0的结果被输出,都是第一列出现重复的,也就是存在 条件判断 ? 做以下改造验证
1 | root@pts/0 $ cat repeat2.txt |awk '{if (a[$1]++ > 0)print}' |
和第3步的结果对比发现,确实做了条件判断
5、所以问题现在定位在两个方面,最主要的是数组中第一次出现的元素的值为何是0
6、进过排查,针对awk数组,有个特性是:
1、直接引用一个数组中不存在的元素时,awk会自动创建这个元素,并且为其赋值为"空字符串"
2、awk中,当变量a的值为字符串时,也可以进行加法运算,如果字符串参与运算,字符串将被当做数字0进行运算
3、空字符串也是字符串,参与运算时,也会被当做数字0进行运算
验证:
直接引用一个数组中不存在的元素时,awk会自动创建这个元素,并且为其赋值为”空字符串”
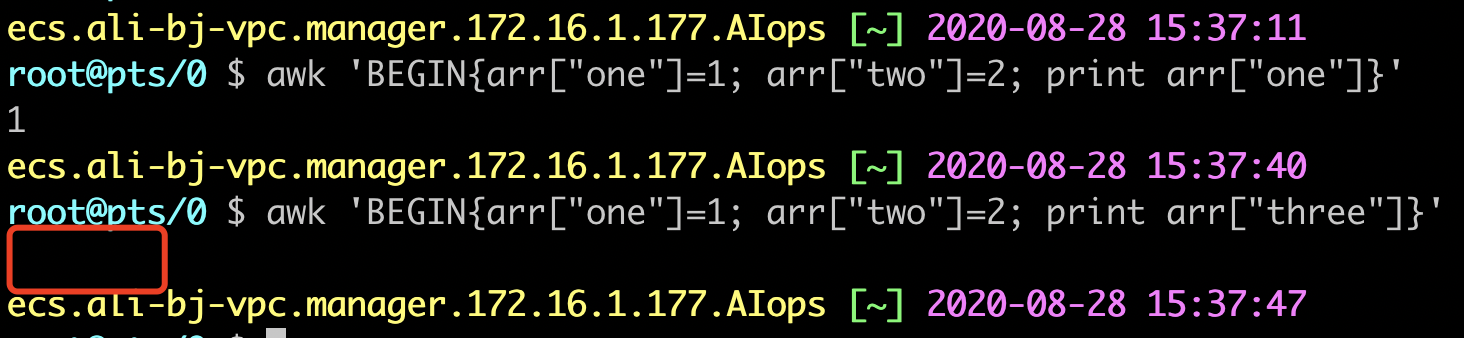
awk中,当变量a的值为字符串时,也可以进行加法运算,如果字符串参与运算,字符串将被当做数字0进行运算

空字符串也是字符串,参与运算时,也会被当做数字0进行运算

综上所述
1、条件判断是可以放到主体block{} 外面的
2、a[$1]++ 遇到第一个出现的记录时,其实就是数组中不存在的一个元素,其默认是为空,计算是被当做0
所以上面的最上面例子中的语句等价于
1 | root@pts/0 $ awk 'a[$1]++>0{print}' repeat.txt |
refer:
[1] http://www.mamicode.com/info-detail-1616775.html
[2] https://www.jianshu.com/p/cae3cccd2ee6