consul跨网段迁移-advertise
背景
对于旧的consul 集群,server在IDC 192.168.3.0/24网段,业务逐步迁移到了阿里云VPC 172.16.0.0/22网段,IDC和阿里云VPC之间是通过专线打通;为了避免因为专线网络抖动等问题导致Consul集群出现异常进而影响业务。故consul server 从 IDC迁移到阿里云VPC
问题
刚开始迁移时,按照常规做法现在VPC新增三台主机,部署启动三个server节点, datacenter 配置保持一致。但是出现问题,新增节点加入到server集群,但是新增的节点没有投票权。
如下图所示,consul-01-vpc的投票选举标识 Voter为False
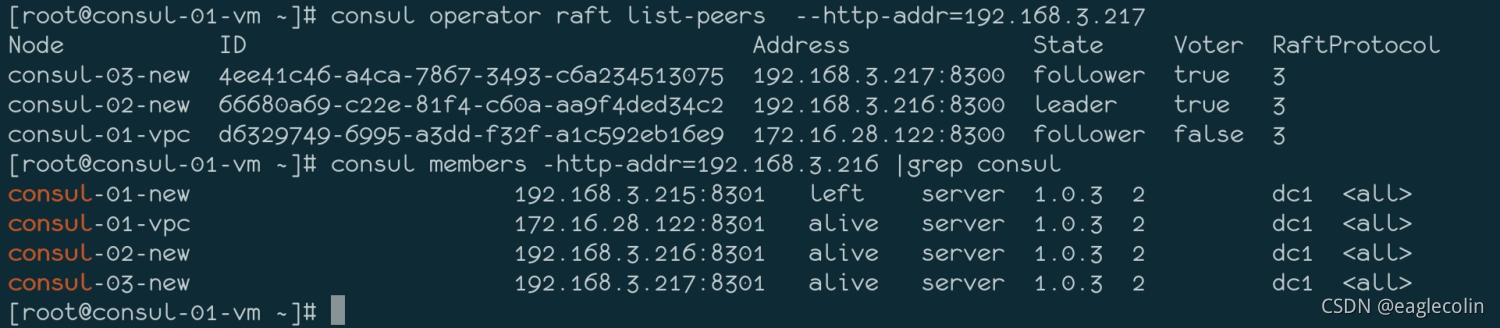
同时在consul-01-vpc的日志中也报错提示No Cluster Leader
1 | consul[15635]: agent: Coordinate update error: No cluster leader |
问题分析
这里简化分析过程,只列举几个核心点
通过对比配置等,排除环境部署不一致的问题,都是通过ansible playbook 推送安装,配置文件一致
猜测是网段的问题,了解到consul多数据中心,其会涉及到跨网络的情况。在IDC
相同网段新增consul-04-vm 部署server启动后,自动加入到现有集群,而且具有投票选举权
所以问题定位到就是跨网段导致的,阅读官方文档发现consul 有 Lan 和 Wan 两种模式,最后问题定位到 配置参数
advertise_addr,该参数等效于命令行参数advertise
官方的解释如下

解析下大概的意思就是
- advertise 配置的地址用于更改我们向集群中其他节点通告的地址。
- 默认情况下,是通过配置项bind 的地址来通告的。但是,在某些情况下,可能存在无法绑定的可路由地址。
- 这个标志允许gossip protocol一个不同的地址来支持这一点
配置项说明参考:https://www.consul.io/docs/agent/options#advertise_addr
问题修复
1、停止新增三台主机上的 consul 服务
2、为了保证新环境的纯净,删除 /data/consul (data_dir 配置项配置)目录下所有内容
3、在配置文件中新增 advertise_addr 值为本地IP,即和bind保持一直
4、启动consul-01-vpc 观察服务正常,然后执行 consul join 192.168.3.xxx (这个IP是旧集群中的任意一个server IP) 加入到旧的集群中去
5、在旧的三个server节点任意一台通过如下命令观察接入是否正常
1 | # 注意:如果配置文件中ports配置项中的http配置的为8500,怎使用如下命令 |
6、如果没有问题,重复上面4、5两个步骤,知道所有新的节点都加入到集群
7、观察没有问题之后,更新client配置中的 retry_join参数,更新为新增的三个server地址
8、观察1天业务没有问题,然后逐步停止 旧的三个server,过程中会发现 Leader节点被选到了新增三个server节点中的一台。
9、观察业务没有问题,旧的三个主机就可以关机回收了
扩展
1、端口说明
8300:集群内数据的读写和复制
8301:单个数据中心gossip协议通讯
8302:跨数据中心gossip协议通讯
8500/80:提供获取服务列表、注册服务、注销服务等HTTP接口。另外consul 提供的UI界面就是通过该HTTP接口访问
8600/53:采用DNS协议提供服务发现功能
这里HTTP/DNS 没有按照标准配置,配置的80/53,具体为什么,在扩展3里面给大家解释
2、常用命令说明
1 | # 查看集群server情况 |
3、Nginx 解析存在的问题
因为是集群,所以不论是 Consul 提供的UI界面访问,还是服务调用 Consul ,都会是优先配置域名解析使用
比如 nginx 中
1 | upstream consul { |
这样配置没有问题,不过consul http是8500端口还是80端口,从配置上都没有问题,但是实际这样出现一个问题,就是有很多 500超时报错如下
1 | 2021/11/24 14:41:45 [error] 29205#0: *6305888994 upstream timed out (110: Connection timed out) while reading response header from upstream, client: 172.17.115.14, server: consul.local.xxxx, request: "GET /v1/kv/upstreams/open-service?recurse&index=76693035 HTTP/1.0", upstream: "http://172.16.28.123:8500/v1/kv/upstreams/open-service?recurse&index=76693035", host: "consul.local.xxxx" |
但是你去检查consul server,服务是没有任何问题的,
如下请求是OK的
1 | curl http://consul.local.xxx/v1/kv/upstreams/open-service?recurse |
加上index就出现超时的问题,出现这个的点在consul 通过index提供 Blocking Queries 默认是有5分钟的等待时间来保证数据的更新。这个超时远大于Nginx配置的超时时间,所以Nginx就出现大量的 500超时报错,
所以把server的http端口修改位80 ,然后直接在业务主机的/etc/hosts 中做解析172.17.18.1 consul.local.xxx,当然这种做法不是最优解。
大家如遇到更好的解决方案,可以留言讨论
关于blocking queries 请参考 https://www.consul.io/api/features/blocking
consul跨网段迁移-advertise
http://blog.colinspace.com/2021/11/30/consul跨网段迁移-advertise/