Jumpserver堡垒机问题和Bug汇总
欢迎关注个人公众号 DailyOps
背景
最近在使用堡垒机过程中发现几个问题,这里做个汇总,希望能对大家有所帮助
问题1、账号不存在,提示”您输入的用户名或者密码不对,请重新输入“,最终错误次数超限,被”锁定“
问题2、配置了”动态用户名(用户名是动态的,登录资产时使用当前用户的用户名登录)“ 会 覆盖主机上同名的SA账号(具有sudo高权限的管理账号)即使从授权中取消该动态用户权限配置
问题3、celery task状态刷新一会online一会offline,导致资产推送系统用户的时候卡死问题
接下来我们一次描述和解答
不存在的账号被锁定
出现的问题是因为运维给开发人员开通账号的时候名字写错,比如开发叫
betty1210,结果运维失误导致告诉开发人员你的账号是betty1211,然后开发人员就开始了艰难的登录之旅
问题发现之旅
1、后台存在账号 betty1210 ,开发使用 betty1211 频繁登录被锁定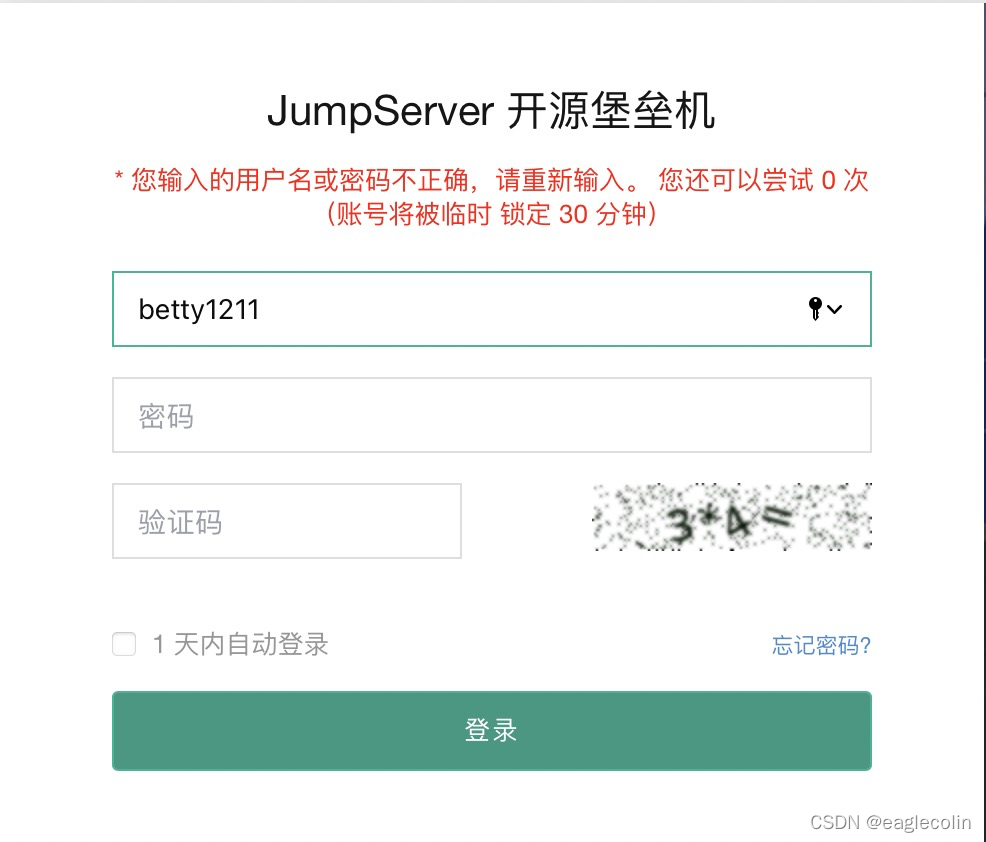
2、管理员登录后台发现,后台实际无 betty1211 用户,存在的是 betty1210 用户;也当然有效用户 betty1210 是没有被锁定的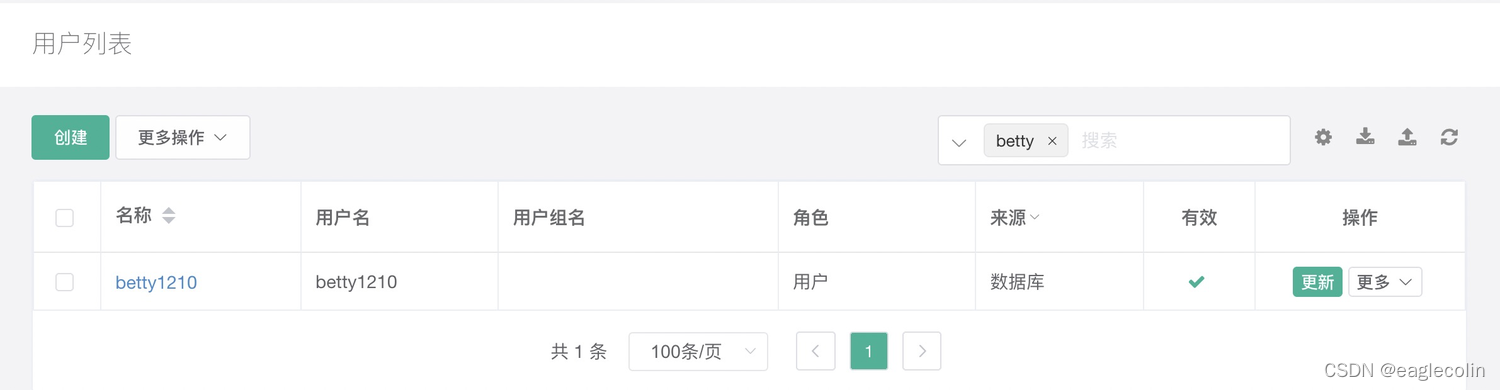
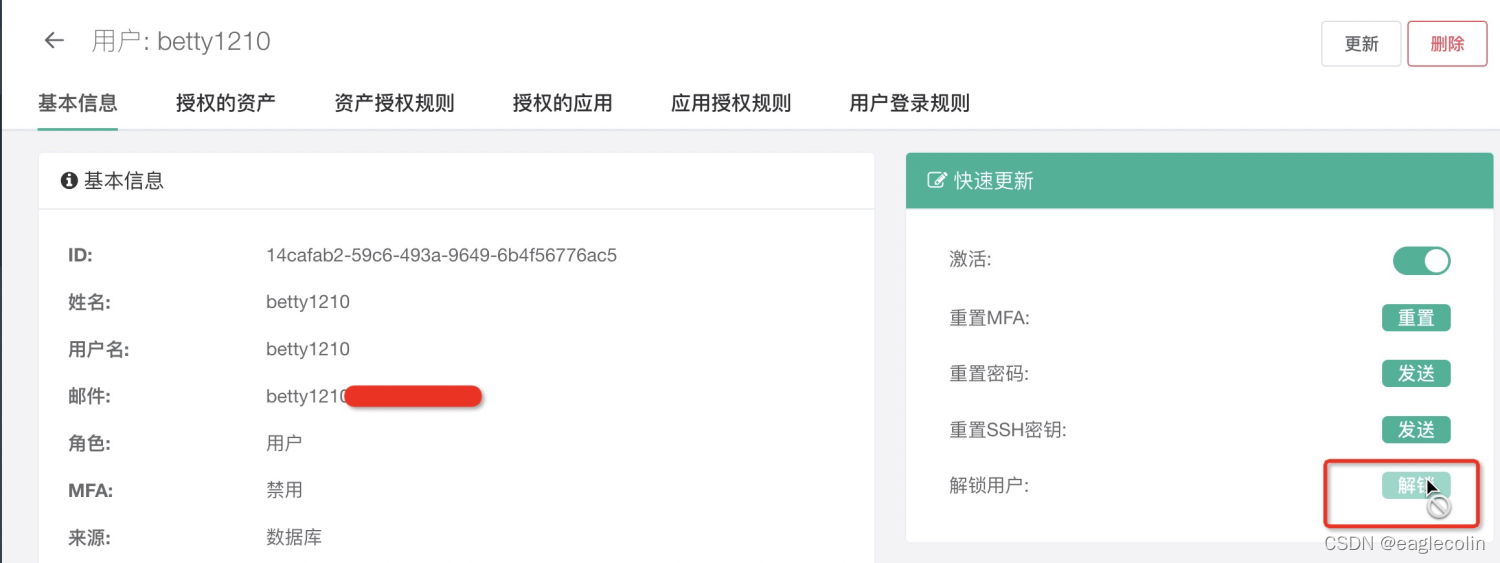
3、然后尝试把 正确用户 betty1210 修改为 错误用户betty1211 ,发现 用户 betty1211 被锁定
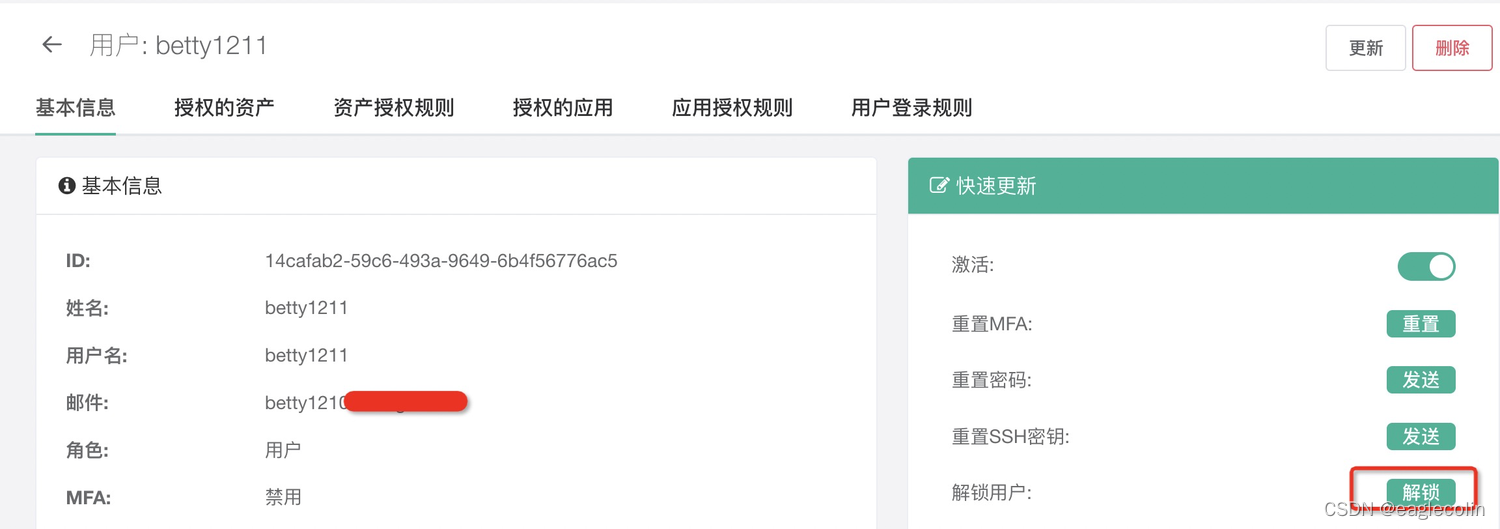
问题总结
个人觉得一般遇到这种问题,大家普通的都会认定是密码不对,然后复制不行,就水写一个个打上去等等尝试,但是账号如果不存在直接提示说该用户不存在 多友好,也不用在怀疑自己密码那些输错了,各种尝试… …
所以各位在设计用户模块的可以站在用户的角度思考下。
动态用户Bug
这个真的是个
Bug
背景
起初公司内部是通过ansible批量管理系统,ansible会给管理员推送SA权限的个人账号,方便管理同时也做好审计日志记录是哪个管理员做的操作
在测试Jumpserver堡垒机的动态用户的时候给管理员James(假设这里管理员叫James)也分配了该系统用户。
注意:动态用户时系统用户的一个类别
之后测试通过之后管理员取消了该动态用户的权限授权,在之后通过镜像(为了方便,特殊SA账号集成到了镜像中)创建新的主机之后发现James账号的SA权限丢失。
—–> 咋就丢了呢?
1、通过分析主机的passwd 和 group 分析发现时间是在主机创建之后,Jumpserver同步系统账号的时间吻合,怀疑是Jumpserver导致
2、创建测试账号JamesTest分配动态用户权限,然后再回收该权限
3、Jumpserver在测试主机上推送动态用户,发现还是会给该主机继续推送JamesTest 动态用户
也验证了确实是Jumpserver的问题导致
4、分析问题
由于篇幅问题,这里简化分析过程,看大家的反馈,有必要的话会整理个更加详细的分析过程
- 主要是通过浏览器发现在新增 资产授权的时候,调用
api/v1/perms/asset-permissions/通过该接口定位到文件perms/api/asset/asset_permission.py
1 | class AssetPermissionViewSet(OrgBulkModelViewSet): |
- 注意到model AssetPermission中 system_users关联了assets.SystemUser,而且有个users_display属性
1 | class AssetPermission(BasePermission): |
- 在
perms/serializers/asset/permission.py文件中分析AssetPermissionViewSet中的serializer_classAssetPermissionSerializer 的perform_display_create中知道授权中涉及到的用户、用户组、资产、资产节点、系统用户都是通过这里进行创建的
1 | class AssetPermissionSerializer(BulkOrgResourceModelSerializer): |
核心就是
instance.users.add,通过之前的model关联关系,知道会把用户和它具有的系统用户报错在中间表assets_systemuser_users中,这里的create进行了perform重写,会写入相关表,但是delete做的时候没有做特殊处理,那么它就只会清理当前model对应的表,也就是
perms_assetpermission_users然后在
资产管理->系统用户->对应的动态用户打开进入到”资产列表中”点击主机后面的”推送“按钮 ,如下图所示,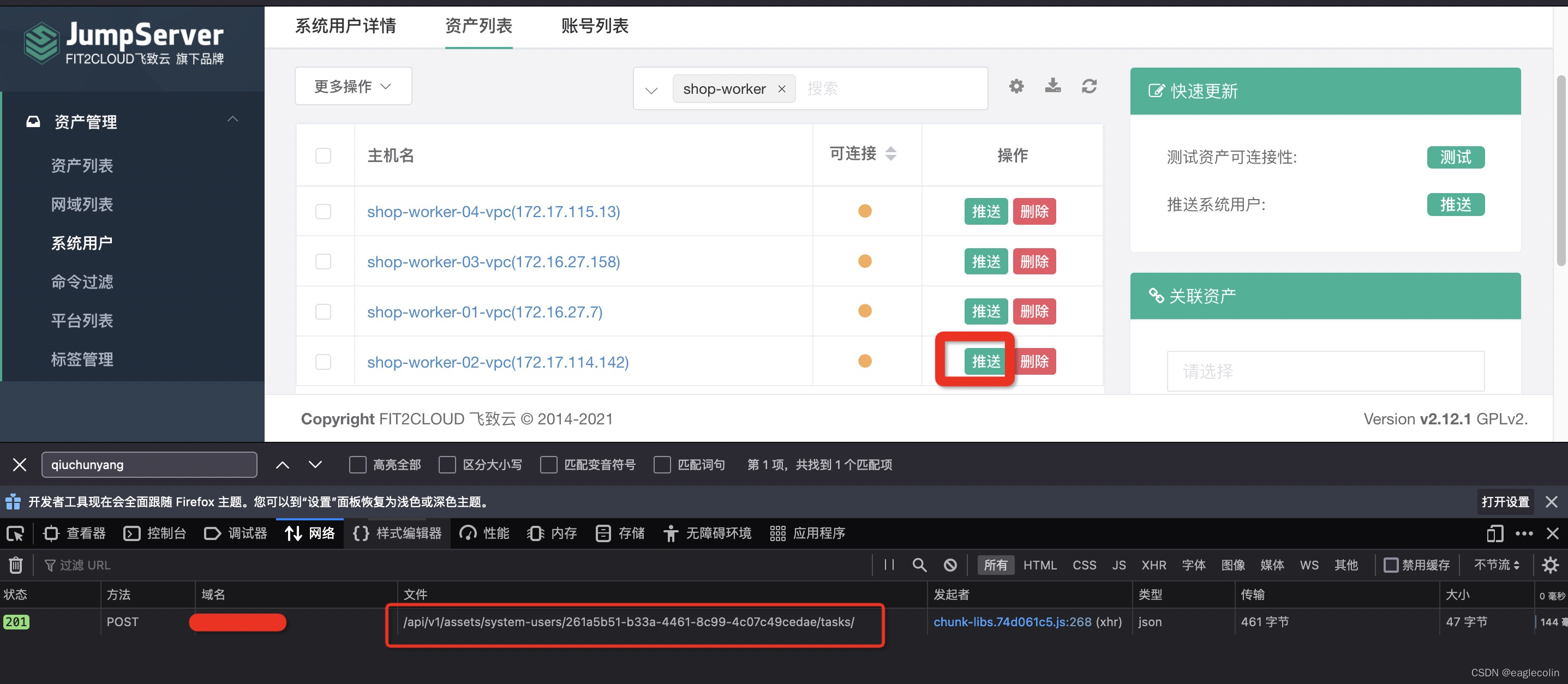 我们发现调用的接口是
我们发现调用的接口是 /api/v1/assets/system-users/261a5b51-b33a-4461-8c99-4c07c49cedae/tasks/,主要涉及到SystemUserViewSet和SystemUsermodel ,系统用户和用户的联系管理就保存在 表assets_systemuser_users中,而 授权清理的时候也没有清理这个表
分析到这里,就知道授权清理存在Bug,只是删除了当前model对应的表数据,但是关联的 systemuser 而产生的中间表数据未清理
解决
知道对应的userid 和 systemuserid 从表 assets_systemuser_users 中清理相关数据,然后重新推送,发现推送记录中已经没有了JamesTest用户
Celery 僵死
Celery的任务监控位于堡垒机 ”作业中心“下的”任务监控“ 中,点击打开新的页面如下图所示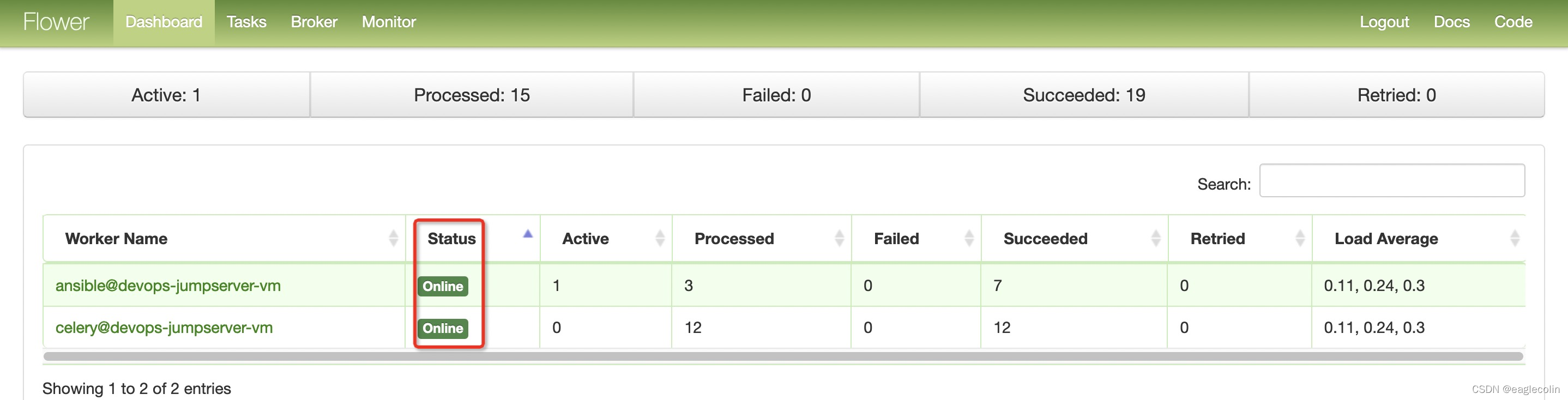
刷新页面这里的status状态一会Online,一会又会Offline,如果尝试推送系统用户,那么遇到的页面的就是**满屏幕的省略号**
主要的原因就是celery僵死导致
1 | [root@devops-jumpserver-vm ]# ps -A -ostat,ppid,pid,cmd |grep -e '^[Zz]' |
尝试清理僵尸进程,发现导致jumpserver掉线,
1 | [root@devops-jumpserver-vm ]# kill -HUP `ps -A -ostat,ppid`|grep -e '^[Zz]'|awk '{print $2}' |
这里需要注意📢:
堡垒机一般都是内网使用,如果一旦出现问题导致不可访问,那就是灾难性的,想登录堡垒机所在主机去排查修复都不可能了,所以一定要有一个备选方案,比如:在堡垒机出现问题的时候可以通过临时绑定一个公网IP然后远程公网SSH登录去修复问题
登录Jumpserver尝试重启Jumpserver服务
1 | # status 发现堡垒机的状态都是 unhealthy |
重启失败,发现对应的容器也出现了unhealthy状态
尝试重启docker
1 | # 重启docker |
看到此处,欢迎点赞、转发,大家一起学习成长哦~
技术文章看累了,来个美图养养眼

Jumpserver堡垒机问题和Bug汇总
http://blog.colinspace.com/2021/12/17/Jumpserver堡垒机问题和Bug汇总/